원티드는 데이터베이스를 AWS의 RDS MySQL을 사용하고 있었습니다. 올해 싱가폴, 홍콩, 대만등의 서비스 지역 확대와 국내 사용자의 증가로 인해서 서비스 속도와 안정성의 문제 원인으로 데이터베이스의 부하라는 판단을 내렸습니다.
간단하게는 RDS instance를 Scale up을하면 당장은 성능에 대한 문제가 해결이 될 수 있지만 근본적인 해결책은 아니고, 다음과 같은 이유로 Aurora를 서비스 환경에 도입하기로 결정을 하게 되었습니다.
- RDS MySQL대비 뛰어난 성능
- 저희 api 기준으로 응답 속도가 50%정도 향상.
- 유연한 확장성
- Cluster 구조로 인스턴스 cluster내의 인스턴스 failover를 통해서 짧은 downtime으로 인스턴스 타입 변경이 가능
- MySQL의 경우 Mutil-AZ로 구성을 하더라도 인스턴스 타입 변경시 DB downtime이 최대 120초 정도 발생
- Auto scaling 지원
- Cluster 구조로 인스턴스 cluster내의 인스턴스 failover를 통해서 짧은 downtime으로 인스턴스 타입 변경이 가능
- 멀티 마스터 지원
- 현재는 seoul region만 사용하고 있지만, 서비스 확대에 따른 멀티리전 사용시 필요한 기능이라고 판단.
실제 서비스에 Mysql에서 Aurora로 이전하면서 있었던,
- 마이그레이션시 고려해야 하는 점
- 마이그레이션 과정
- Aurora failover에 대한 대응방법
에 대해서 정리하고자 합니다.
MySQL -> Aurora 마이그레이션 고려사항
Aurora는 MySQL 및 PostgreSQL 호환 관계형 데이터베이스이기 때문에 Application에서의 별도의 DB query의 수정없이 사용할 수 있습니다. DB query의 수정 없이 사용할 수 있는 점은 맞지만, 반드시 고려해야 하는 점이 한가지 있습니다. RDS MySQL과 RDS Aurora의 HA 구조가 다르고, Aurora에서 Failover 발생시 application 에서의 적절한 대응이 필요합니다.
Mysql의 경우 2대의 인스턴스가 Master-Slave 구조의 HA 구성이라면, Aurora의 경우는 Cluster 구조로 Master-Slave 개념이 아닌 Writer-Reader 구조입니다. 이러한 Cluster 구조이기 때문에 DB endpoint도 인스턴스에 할당된 endpoint가 아닌 cluster에 할당되어 있는 cluster endpoint 와 reader endpoint를 사용해야 합니다.
Aurora의 Cluster endpoint, Reader endpoint의 구성은 아래의 그림과 같습니다.
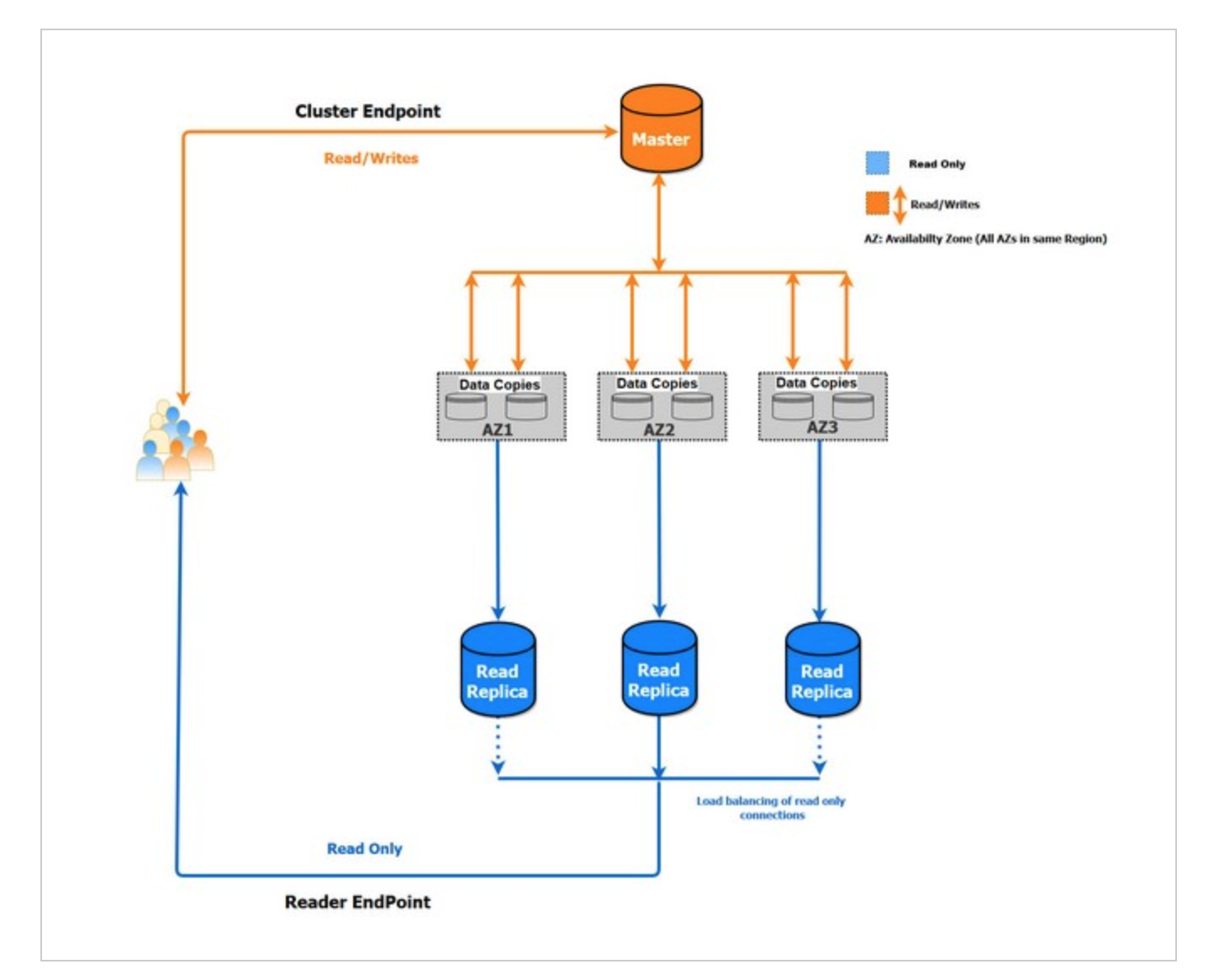
위의 그림을 보면, Cluster endpoint가 Master 인스턴스를 바라보고 있고, Reader endpoint가 다수의 read replica 인스턴스를 바라보고 있는 모습입니다. Aurora의 경우 Auto scaling을 제공하는데, 이것은 reader 인스턴스를 늘려주는 것입니다.
Aurora의 endpoint 주소는 AWS management console의 cluster 메뉴에서 확인이 가능합니다.
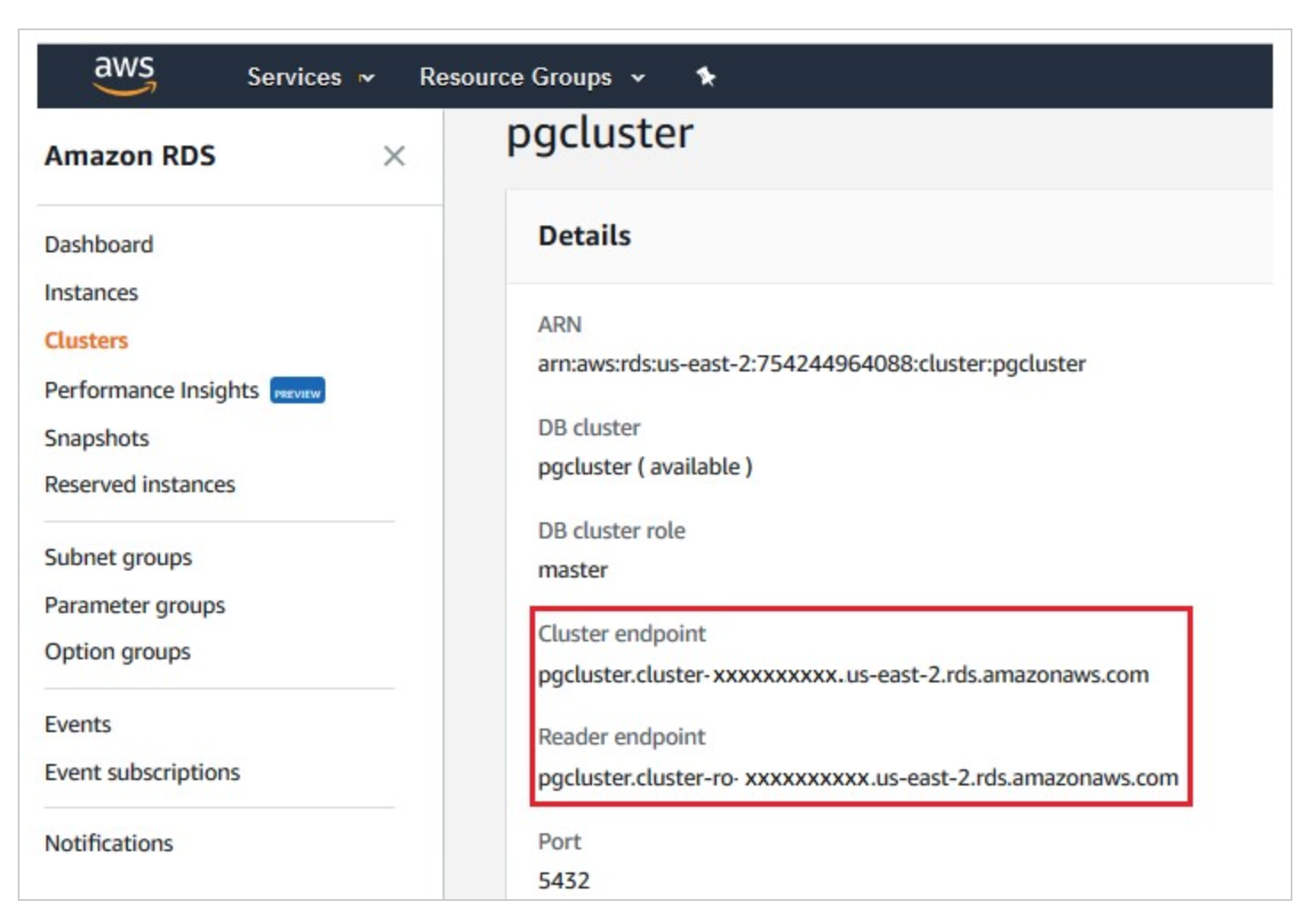
만약에 Cluster endpoint가 아닌 인스턴스에 할당되어 있는 endpoint를 Database의 주소로 사용한다면, failover 발생 시, 아래와 같은 에러를 접할 수 있습니다.
1290 The MySQL server is running with the –read-only option so it cannot execute this statement
Failover 발생시 application에서 가장 고려해야 하는 점은 cluster endpoint가 바라보고 있는 실제 인스턴스가 변경되기 때문에 DB Connection을 새로 맺어 주어야 합니다. Failover 이후에 계속 동일한 DB connection을 사용한다면, 해당 connection의 인스턴스는 reader로 failover 되었기 때문에 DB write 요청에서 에러가 발생하게 됩니다.
MySQL -> Aurora 마이그레이션 과정
MySQL에서 Aurora로 마이그레이션하는 방법은 여러가지가 안내되어 있습니다.
Amazon RDS MySQL DB 인스턴스에서 Amazon Aurora MySQL DB 클러스터로 데이터 마이그레이션
저희가 마이그레이션한 방법은 위의 내용과는 조금 다릅니다.
- Aurora replication 생성
- replication을 생성 할 때, Master DB에서 backup 작업이 발생하는데, 이 때 CPU 자원을 많이 사용하기 때문에 가능하다면 사용자가 적은 시간에 하는걸 추천합니다.
- Cross region replica가 설정되어 있는 경우 Aurora replica 생성이 불가능합니다. (만약 설정되어 있다면 삭제하고 진행해야 합니다.)
- 서비스 중단
- Aurora replication promote
- 서비스 Database endpoint(Aurora cluster endpoint) 변경
- 서비스 동작 확인
- 서비스 재시작
위와 같은 순서로 마이그레이션 후 서비스 Database를 변경하였습니다. 실제로 30분 정도의 서비스 중단이 있었습니다.
Failover에 대한 대응
위에서도 잠깐 언급을 했지만, Aurora의 경우 cluster 구조이고 failover가 발생하면 writer 역할을 하던 인스턴스가 reader 인스턴스가 되기때문에 DB connection 관리를 제대로 하지 못하면, failover가 발생 했을 때 DB write 요청이 에러가 발생해서 서비스에 치명적인 영향을 줄 수 있습니다.
저희는 python의 sqlalchemy를 사용하고 있고 저희가 시도했던 방법들은 다음과 같습니다.
SQLALCHEMY_POOL_RECYCLE설정을 짧게 주어서 DB connection을 주기적으로 하게 하는 방법- 이 옵션은 Flask-SQLAlchemy의 옵션으로 SQLAlchemy에서는 create_engine 함수에 pool_recycle 파라메터를 주어아 합니다.
- flask app context가 삭제될 때 특정 exception이 발생하는 경우, sqlalchemy pool connection을 다시 맺도록 하는 방법
- sqlalchemy session을 checkout 할 때, DB instance의 상태가
read only인지 확인하고read only인 경우DisconnectionErrorexception을 raise 하여 sqlalchemy에서 다시 connection pool을 맺도록 하는 방법
결론적으로 저희가 적용한 방법은 3번째 방법입니다.
첫번째 방법의 경우, DB connection을 너무 자주 맺다보니, DB connection에 대한 오버헤드 때문에 성능적인 부분에서 손해를 보는 문제가 있었습니다.
두번째 방법의 경우, 문서상에 나와 있는 방법이 아니고 저희가 sqlalchemy code를 보고 시도했던 방법인데, 동작상의 문제는 없었지만 좋은 방법같지는 않아서 적용하지 않았습니다.
저희가 적용한 세번째 방법은 아래와 같습니다.
@event.listens_for(Pool, 'checkout')
def ping_connection(dbapi_connection, connection_record, connection_proxy):
""" https://docs.sqlalchemy.org/en/rel_1_1/core/pooling.html
?highlight=disconnect#disconnect-handling-pessimistic """
cursor = dbapi_connection.cursor()
try:
cursor.execute("SHOW VARIABLES LIKE 'innodb_read_only'")
row = cursor.fetchone()
if row[1] == 'ON':
connection_host = dbapi_connection.get_host_info().split()[0]
if connection_host != MYSQL_HOST_READ_REPLICA:
raise exc.DisconnectionError()
except exc.OperationalError:
raise exc.DisconnectionError()
cursor.close()
- http://docs.sqlalchemy.org/en/rel_1_1/core/pooling.html#disconnect-handling-pessimistic 페이지의 내용을 참고했습니다.
마치며…
Aurora를 실제로 서비스에 적용한지 오래되지는 않았지만, 아래와 같은 부분에서 만족을 하고 있습니다.
- 성능적인 부분에서의 개선
- Failover를 통한 유연한 scale up 또는 scale down
- 멀티 마스터에 대한 기대?
Aurora를 처음 사용하시는 분은 반드시 다음과 같은 부분에 대해서 준비가 필요하다고 생각됩니다.
- Aurora cluster 구조의 이해
- Aurora failover에 대한 application 상에서의 대응방법